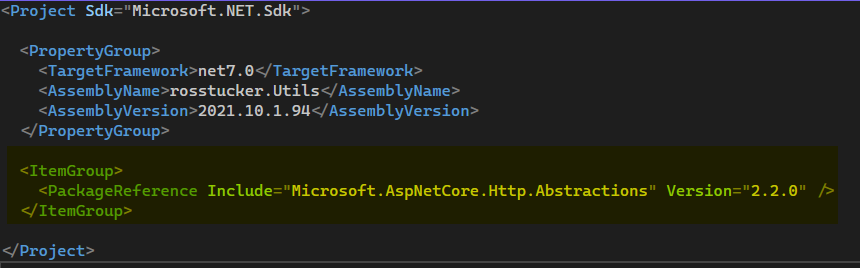
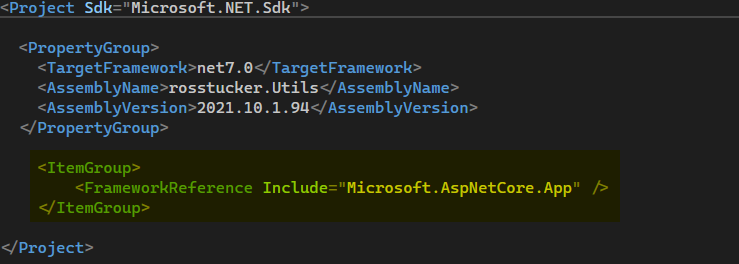
First update your system
apt update apt upgrade
Next download google-chrome
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
Next install ‘google-chrome’
dpkg -i google-chrome-stable_current_amd64.deb
If you have a problem with your dependencies after the previous step, run the following command then try again the previous step.
sudo apt -f install
Verify your version of google-chrome
google-chrome --version # Google Chrome 123.0.6312.86
Create a new console program
dotnet new console -n SeleniumExample cd SeleniumExample
Install required packages
dotnet add package Selenium.WebDriver dotnet add package Selenium.WebDriver.ChromeDriver
Edit your Program.cs file and replace its contents with the code below.
using System;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
class Program
{
static void Main(string[] args)
{
// Set up the ChromeDriver
var options = new ChromeOptions();
options.AddArgument("--headless");
using var driver = new ChromeDriver(options);
// Navigate to a website
driver.Navigate().GoToUrl("https://www.google.com");
// Wait for the results to load and display the title
driver.Manage().Timeouts().ImplicitWait = TimeSpan.FromSeconds(5);
Console.WriteLine(driver.Title);
// Close the browser
driver.Quit();
}
}
Run the program, it should show the title of the google.com webpage