See also the LangChain cookbook.
First of all install the langchain tool. LangChain is a framework for developing applications powered by language models.
I started with a brand new Ubuntu 22.04 server installation. Download the server here and install with everything default. Be sure to install the OpenSSH server.
I used virtual box to host the Ubuntu machine.
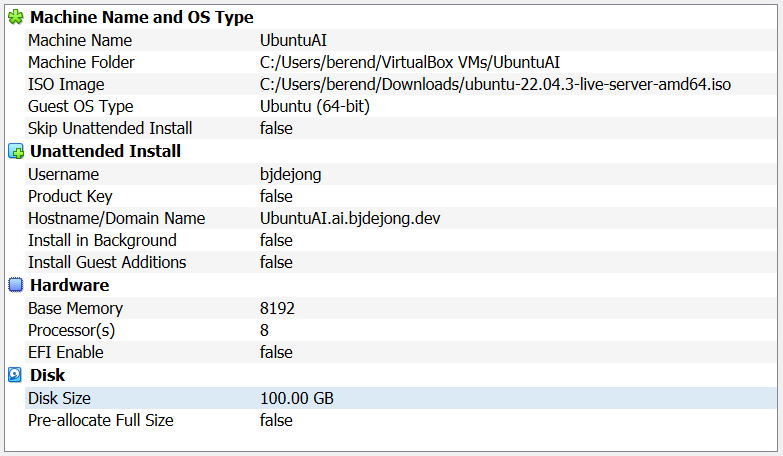
After installation (could take a while) spin the machine up and connect to it from a Windows terminal (better GUI) with ssh. If you cannot connect to your new virtual machine change the Network adapter setting from NAT to Bridged.
Ubuntu comes with python install, check version:
python3 --version # Python 3.10.12
First of all install pip onto your new virtual machine:
sudo apt update sudo apt upgrade sudo apt install python3-pip pip3 --version # pip 22.0.2 from /usr/lib/python3/dist-packages/pip (python 3.10)
Now install LangChain from the pip repositories:
pip install langchain pip show langchain # Name: langchain # Version: 0.0.310 # Summary: Building applications with LLMs through composability
We also need some additional modules:
Add a .env file for use with dotenv, add 1 line to this file with the following contents:
OPENAI_API_KEY=[YOUR KEY HERE]
Now install the openai module which contains the llm stuff:
pip install openai pip show openai # Name: openai # Version: 0.28.1 # Summary: Python client library for the OpenAI API
We will use ChromaDb as our vector store to store embeddings from PDF’s. Install chromadb, tiktoken, dotenv and pypdf.
pip install chromadb tiktoken pypdf dotenv pip show chromadb # Name: chromadb # Version: 0.4.13 # Summary: Chroma.
Now your environment is setup. We can start to build a vector database with a sample PDF. Download for example this PDF. Then create a python script as shown below:
from dotenv import load_dotenv
from langchain.vectorstores import Chroma
from langchain.document_loaders import DirectoryLoader
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
load_dotenv()
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
loader = DirectoryLoader(".", glob='./*.pdf', loader_cls=PyPDFLoader)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter()
texts = text_splitter.split_documents(documents)
vectordb = Chroma.from_documents(documents=texts,
embedding=embeddings, persist_directory="./db")
The script above will create a SQLite database in the db subfolder. It reads all the pdf files in the current folder and stores them in de SQLite database as embeddings.
Now we can start querying out PDF (database). The script below is an example of how to query your PDF through the use of the vector database.
import argparse
from langchain.chains import RetrievalQA
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv
load_dotenv()
chroma_db_directory = "./db"
parser = argparse.ArgumentParser(
description="Returns the answer to a question.")
parser.add_argument("query", type=str, help="The query to be asked.")
args = parser.parse_args()
embedding = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=chroma_db_directory,
embedding_function=embedding)
retriever = vectordb.as_retriever(search_kwargs={"k": 10})
prompt_template = """
Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know and nothing else.
Don't try to make up an answer.
Answer questions only when related to the context.
{context}
Question: {question}
"""
PROMPT = PromptTemplate(template=prompt_template,
input_variables=["context", "question"])
chain_type_kwargs = {"prompt": PROMPT}
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model_name="gpt-4",
temperature=0, verbose=True),
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs,
verbose=False,
return_source_documents=True)
llm_response = qa_chain(args.query)
print(llm_response["result"])
You can now ask question about the PDF, for example:
python3 q.py "What does LSP mean?" # LSP stands for Liskov Substitution Principle. It is a principle in object-oriented programming that states functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it. This principle was first introduced by #Barbara Liskov. Violating this principle can lead to issues in the program, as functions may need to know about all derivatives of a base class, which violates the Open-Closed principle. python3 q.py "Who is Barbara Liskov?" # Barbara Liskov is a computer scientist who first wrote the Liskov Substitution Principle around 8 years prior to the context provided. python3 q.py "Create a summary of 10 words" The Liskov Substitution Principle is crucial for maintainable, reusable OOD.
